在图书馆里,每一本书都要被编目,这样才能方便查找和利用。于是,很早就有人想到,网上所有的资源也需要“编目”。
如果要对网络资源编目,首先就必须有一套“编目规则”。资源描述框架(Resource Description Framework ,简称RDF),就是一套W3C提出的描述网络资源的方法。
RDF的基本思想很简单,就是说任何网络资源都可以唯一地用URI(统一资源标识符,Uniform Resource Identifier)来表示。在这里,可以简化地将URI理解成网址URL。
比如,世界第一大网站Yahoo!首页的网址是http://www.yahoo.com/,那么它的首页就可以用这个网址来唯一代表。
有了这个识别符以后,网络资源的其他特性都用“属性(Property)”=“属性值(Property value)”这样的形式来表示。
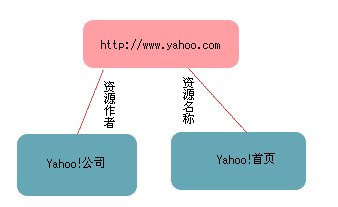
请看上图,最顶部的方框表示网络资源http://www.yahoo.com/,下面的两个方框表示两个属性关系,一个是“资源作者=Yahoo!公司”,另一个是“资源名称=Yahoo!首页”。
根据RDF的定义,资源本身是主语subject,属性名称是谓语predicate,属性指是宾语object。对网络资源的描述就采用主-谓-宾的形式。
RDF本身用xml文件的形式表示,比如上图写成xml文件就是:
Yahoo!公司资源作者>
Yahoo!首页资源名称>
这个xml文件不是很规范,主要是为了说明问题。
RDF强大的地方在于,它只规定了主-谓-宾这种描述形式,至于谓语和宾语到底是什么,完全可以根据不同需要自由选用。因此,RDF才能定义为“资源描述框架”,而不是“资源描述方法”。
用于RDF的最常见谓语和宾语,是都柏林核心(Dublin Core),简称DC。它是一套用于描述信息的元数据,一共有15个标签,也就是15个谓语和宾语的组合,其中常见的标签包括Title,Creator,Subject等等。
采用了都柏林核心以后,基本上所有的网络资源都可以用RDF描述出来,因此初步实现了对网络资源进行编目的目的,为下一步机器化处理和最终语义网的实现打下了基础。
以下我举一个实例。
2年前的今天,2006年2月25日,我写了一篇网志《学科和采矿》,用RDF对这篇网志进行编目,就是下面的结果:
xmlns:trackback="http://madskills.com/public/xml/rss/module/trackback/"
xmlns:dc="http://purl.org/dc/elements/1.1/">rdf:about="http://www.ruanyifeng.com/blog/2006/02/post_179.html"
trackback:ping="http://www.ruanyifeng.com/cgi-bin/mtype/mt-tb.cgi/251"
dc:title="学科和采矿"
dc:identifier="http://www.ruanyifeng.com/blog/2006/02/post_179.html"
dc:subject="History"
dc:description="今天突然想到一个比喻:选择不同的学科就好像采矿一样。 有的矿是新发现的矿物品种,埋藏浅,品味高,容易开采。选择这样的矿,很容易出成果。某些新兴学科大概就是这样的矿,计算机科学可以算一个例子。..."
dc:creator="ruanyf"
dc:date="2006-02-25T20:52:32+08:00" />
这是一个规范的xml文件,可以实际使用。请注意标成黑体的那几行。首行“rdf:Description”,这是RDF规定使用的标签,表示主语subject,后来的“rdf:about”属性用来表示资源的标识符,也就是url,它唯一地确定了一个网络资源。其他属性中的dc:title、dc:identifier、dc:subject、dc:description、dc:creator和dc:date,分别表示题目、标识符、主题、简介、创造者、日期,这几项都属于都柏林核心,等号后面是相应的值。至于trackback:ping属性,这一项在都柏林核心中没有规定,但是也可以加上去,从中可以看到RDF资源描述框架的灵活和强大。